macOS 大模型本地部署日常使用
date
Jan 21, 2024
slug
macOS 大模型本地部署日常使用
status
Published
tags
LLM
macOS
summary
macOS 大模型本地部署日常使用
type
Post
我的日常开发设备是 M2 Max 64G,最近想要测试下在本地起大模型作为日常使用是否可行,选了 llama.cpp 和 mlx 这两个推理框架作为对比。mlx 是苹果推出的 Apple silicon 专用机器学习框架,除了推理任务,也可以进行模型训练,llama.cpp 刚开始是专为 Apple silicon 开发的推理框架(现在也支持 Linux 和 Windows),支持多种量化方法,从 2bit 到 8bit,tradeoff 在于资源消耗和模型能力的退化,一般推荐 4bit 做推理,性能损失在可接受的范围。
关于测试模型选择,在 7B~34B 这个区间,大模型的能力随着参数的增加提升还是很明显的,虽然现在有很多很强的 7b 模型号称达到了两倍参数量模型的效果,不过我觉得以后对于配置还行的(非入门级)设备,14b/34b 的 int4 量化版会是跑本地模型的首选。这次测试选了自己基于 qwen-14b SFT + DPO 训练的模型做测试,虽然这个模型跑过很多评估集,但其实我自己没怎么日常试用过,或许从日常使用中能够获得新的训练调优灵感、方向。
推理速度 benchmark 结果
mlx 版本:0.0.10
框架 | 精度 | 权重大小(GB) | 内存占用(MB) | 速度(tokens/s) |
mlx | int4 | 8.7 | 9638.88 | 17.33 |
mlx | fp16 | 28 | 21130.97 | 8.78 |
llama.cpp | int4(q4_1) | 9.0 | 8592.7 | 30.25 |
llama.cpp | int8 | 15 | 14358.31 | 21.05 |
llama.cpp | fp16 | 28 | 27023.94 | 12.5 |
从表格中可以看到当前阶段 llama.cpp 还是快挺多的,毕竟是专门优化的推理库。
客户端
调研了一圈发现支持本地模型的客户端基本都是基于 llama.cpp 的,例如 lmstudio 和 Ollama。lmstudio 需要升级到 macOS 13.6,我的系统比较老,就没测试,但是整个界面给我的感觉是太啰嗦了,而且也没有全局快捷键、预定义 prompt 模版之类的功能。
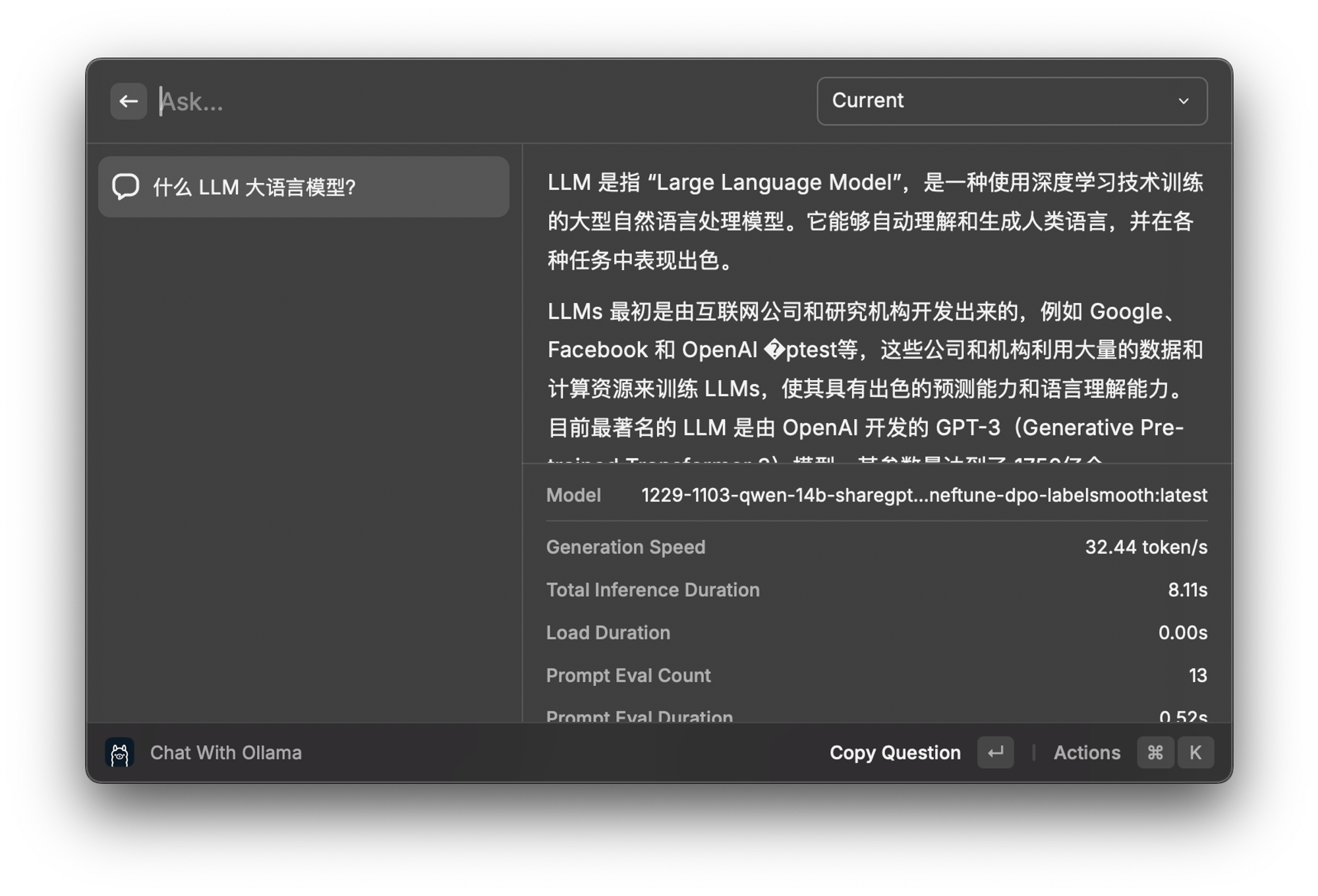
Ollama 有推荐一些客户端,看了一圈感觉都不是很喜欢,最后选择了 Raycast 的 Ollama 插件。ollama 加载自定义的 gguf 模型文件需要有一个额外的转换过程 `ollama create`,这个过程中可以定义模型 sampling 的一些参数,例如 temperature 、template 等,ollama 插件中的预制 prompt 模版是使用 system 实现的,所以 `ollama create` 时一定要加上 system,我用的是 chatml 的 template。
这个插件的完成度很高,可以多轮对话,也可以获得光标选取的文本,不过创建自定义模版感觉还是不是很方便,就先这样用着吧。