DBNet 长短文本检测问题
date
Aug 8, 2021
slug
DBNet
status
Published
tags
Deep Learning
OCR
Computer Vision
DBNet
Text Detection
summary
type
Post
DBNet 是目前比较流行的基于分割的 OCR 文本检测算法,可用于检测任意形状的文本,并且后处理简单,速度快,在各大 OCR 项目中都有其实现,例如百度的 PaddleOCR,商汤的 mmocr。在实际应用中发现,对于长短文本,模型的表现会不一致,对于较短的文本行,最后的文本框会较为”宽松“,而对于较长的文本行,最后的文本框会较”紧凑“,严重时可能会对文本行截断。值得一提的是 PaddleOCR 的模型几乎没有这个问题,而 mmocr 的模型这个问题则比较严重(两个项目的训练数据不同,这样对比可能不太合适)。


上面的图片来自 mmocr issue#376 ,从图中可以看出,短文本的效果还不错,较长的文本出现了截断的现象(例如右上角的“尼康官方授权店”),这肯定会影响识别结果。一个解决的办法是增大 DBNet 后处理过程中使用的膨胀系数,但是这样会导致短文本周边的 padding 过大,同样会影响识别模型的准确率(虽然没有截断的影响那么大)。
问题原因
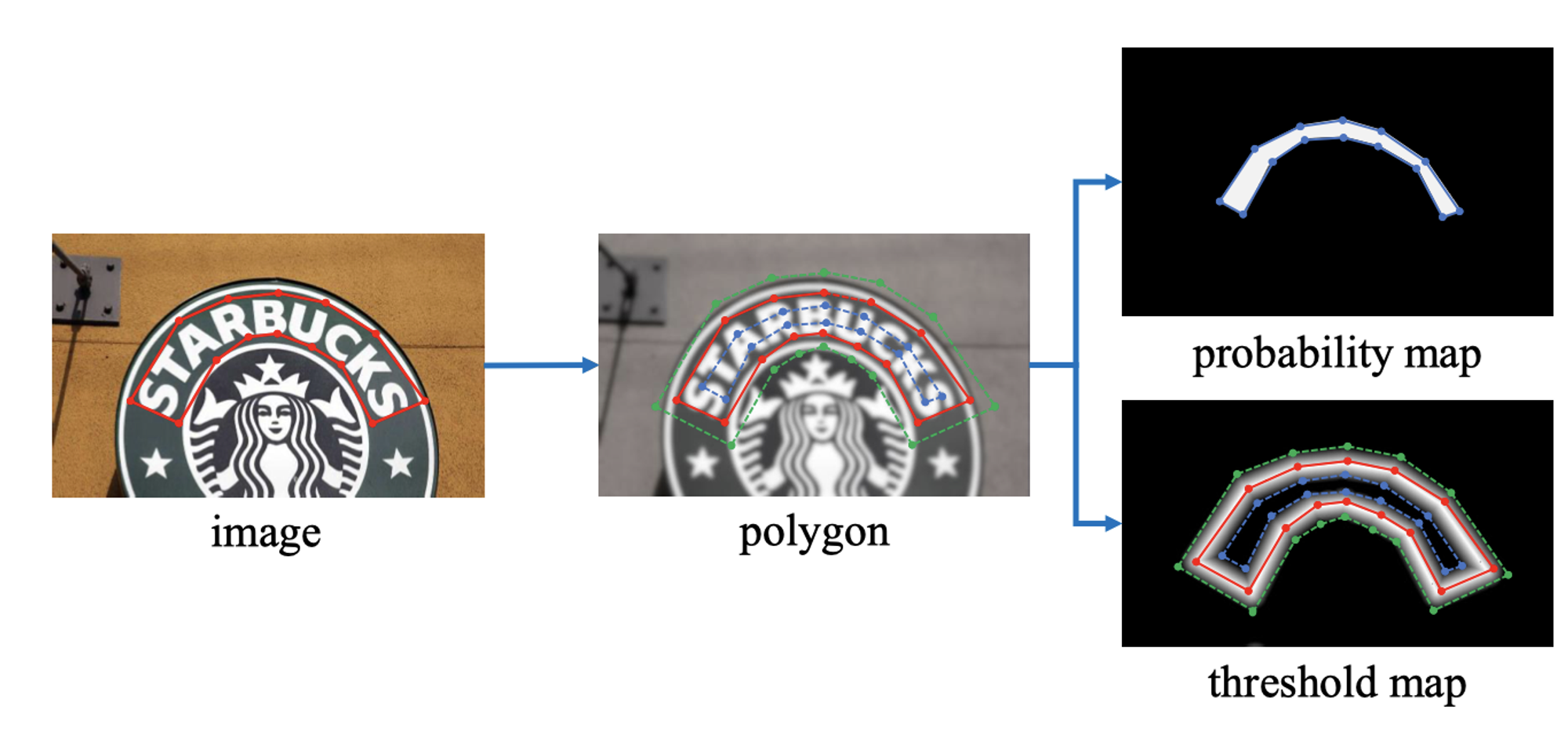
DBNet 中生成文本框 label 时,使用
Vatti clipping algorithm 对原始文本框进行收缩,收缩距离 D 由以下公式计算,其中 A 为多边形的面积,L 为多变形的周长, 为收缩系数,论文中使用 0.4。在推理阶段,DBNet 的后处理包含三步:
- 网络输出的概率图使用固定阈值转化为二值图
- 在二值图上找到连通域,每个连通域代表一个文本框实体
- 计算文本框膨胀(dilate)的距离 ,其中 为连通域的面积, 为连通域的周长, 为膨胀系数,论文中使用 1.5
我们假设模型能够正确地学出 gt 标签,使用论文中的公式以及收缩/膨胀系数进行可视化验证(示例代码见文末):
- 构造三个高度相同,长度不同的文本框,记为 text1
- 按收缩系数 0.4 收缩文本框,再使用 1.5 对文本框进行膨胀,结果记为 text2
- 使用 text1 的文本区域减去 text2 的文本区域,记为 text3

上图的最后一张图为 text3,白色部分表示 text1 比 text2 多出来的部分,可以看到长文本收缩/膨胀后的结果明显比原先的文本框小一圈,既长文本会框的更加紧凑。
可能的解决方法
在训练阶段修改计算 shrink 距离的方式,原文由于目标是任意形状的文本检测,所以使用了适应性较强的计算公式,如果需求简化为矩形框(水平或倾斜),可以换成按照框的高度计算距离,或者对于原公式计算出的距离设一个 MAX 上限,防止长文本 shrink 距离过大